Blog

Introducing Services in Steadybit to Enable Turnkey Reliability Testing and Risk Assessment
24.03.2026With Services in Steadybit, you can now easily view test coverage, run associated reliability tests, and surface business-critical risks.

Using Grafana and Steadybit MCP Servers in LLM-Based Reliability Workflows
17.03.2026In this article, we outline how you can build new AI-powered reliability workflows with the combined power of the Grafana & Steadybit MCP servers.

How to Prepare Your Services to Handle Availability Zone Outages
02.12.2025In this article, we explain how you can use chaos engineering principles to run availability zone outage experiments on your systems to ensure that traffic is rerouted correctly.

Unlocking New Reliability Workflows with the Datadog and Steadybit MCP Servers
15.10.2025The combination of Datadog's observability expertise and Steadybit's chaos engineering platform enables reliable systems and more resilient teams. In this post, we explore some example prompts around various chaos engineering topics.

How to Check Kafka Consumer's Reaction to Record Loss
15.10.2025In this guide, we will walk through how to design and run an experiment to check your Kafka consumer's reaction to record loss. We'll show you how to simulate this failure safely, monitor the results, and gain confidence in your system's reliability using chaos engineering.

How to Test Kubernetes Deployment Degradation When RabbitMQ Is Down
18.09.2025Learn how you can proactively test your systems to validate graceful degradation when RabbitMQ is unavailable and ensure system reliability for your end users.

How to Test Load Balancer Failover During an AWS Availability Zone Outage
16.09.2025Learn to proactively test your load balancer's cross-zone failover with chaos engineering to ensure system resilience during an Availability Zone (AZ) outage.

How to Validate AWS ECS Auto Scaling Policies with Chaos Engineering
12.09.2025Learn how to configure auto-scaling for AWS ECS Services to handle variable CPU demands, and validate performance reliability with a chaos experiment.

Testing Kubernetes Cluster Performance During High Latency from a 3rd-Party Service
11.09.2025See why high latency from 3rd party dependencies can be a risk to Kubernetes cluster reliability and how to run chaos experiments to test their resilience.

The Role of Chaos Engineering in the Reliability Pillar of the AWS Well-Architected Framework
11.09.2025In this post, we explore the role of chaos engineering within the Reliability pillar of the AWS Well-Architected Framework, and dive into how organizations can utilize chaos experiments to continually optimize their resilience for each of these categories.

Using Open Source Tools to Get Started with Chaos Engineering
09.09.2025Explore the top open-source tools for getting started with chaos engineering, and see why commercial tools can be useful in actually scaling a reliability program across an organization.

Running Reliability Engineering Workshops for More Resilient Teams
28.08.2025We’ve put together a set of simple, hands-on workshops you can run in a safe chaos engineering environment with Steadybit. Sure, you could dive straight into a full-blown GameDay to explore human reliability — but that’s a big lift. Starting small with workshops is a much easier (and smarter) way to get going.

Adding Load Testing to Chaos Engineering
29.07.2025Load testing tells you how your system performs; chaos engineering shows how it fails. With Steadybit, you can run both at once to uncover what truly breaks under real-world pressure.

Top Chaos Engineering Tools Worth Knowing About (2026 Guide)
17.07.2025This guide breaks down the top chaos engineering tools of 2025 and what makes them actually useful for teams shipping production code.

Chaos Engineering Doesn’t Create Chaos
17.07.2025Chaos engineering is a way to uncover hidden issues in your system before they impact customers.

When Was the Last Time You Tested a Real Failure?
05.06.2025If you haven’t tested a real failure recently, your systems might not be as resilient as they seem. Real stability comes from exposing and addressing risks before they break things.

Steadybit Now Supports Running Experiments on Windows
04.06.2025Steadybit now supports chaos engineering on Windows Hosts. This new extension makes it easy to bring Windows Hosts into your existing chaos engineering workflows.

Bring AppDynamics Health Rules into Your Steadybit Chaos Experiments
28.05.2025With our new AppDynamics integration, you can run experiments in Steadybit and see immediately if health rules are violated or not during your fault injections.

Steadybit is Now SOC 2 Type 2 Certified
07.05.2025We are excited to share that Steadybit is now officially certified to be compliant with SOC 2 Type 2, an industry benchmark that signifies strong organizational reliability and security practices.
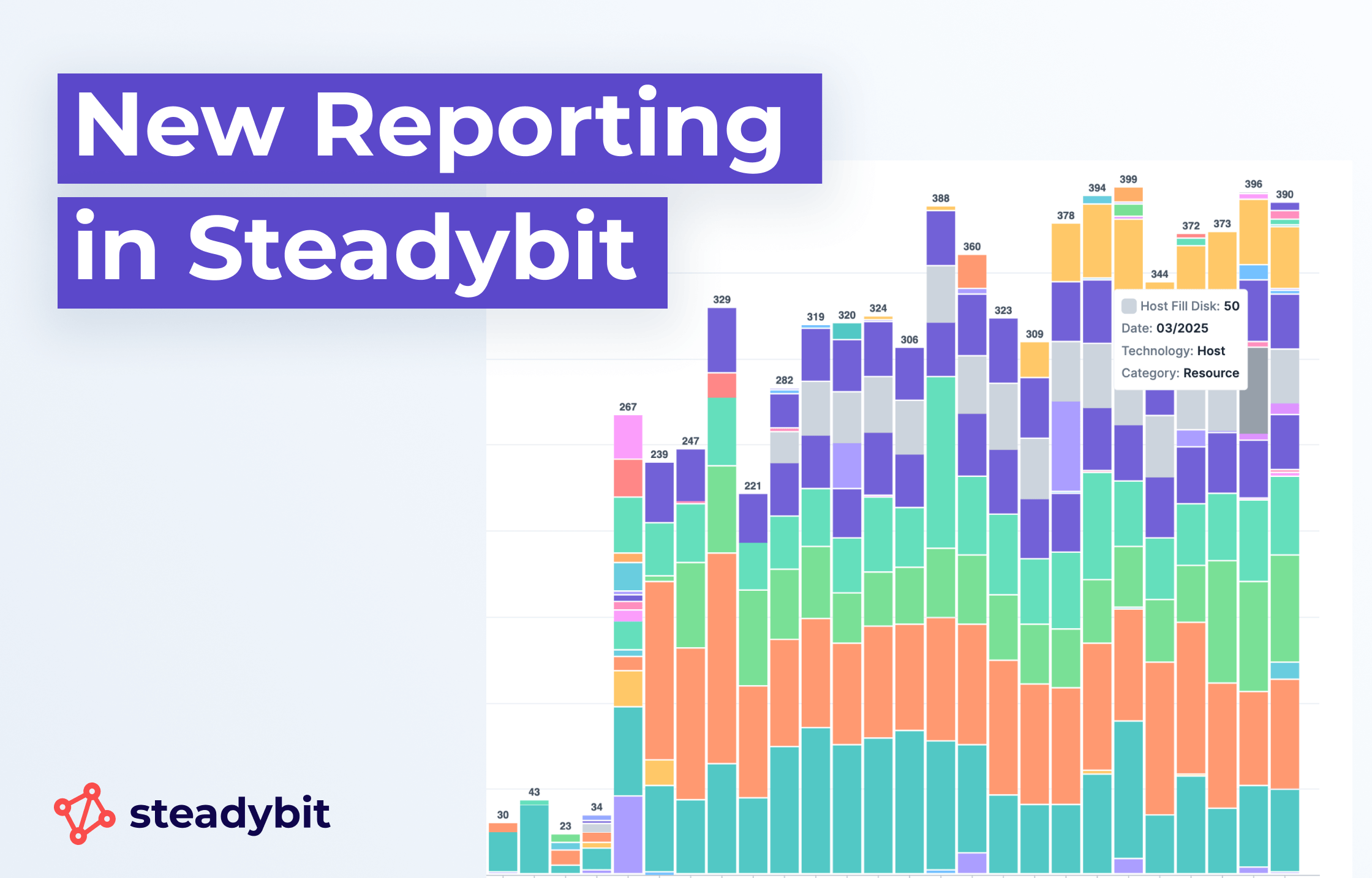
Track Your Chaos Engineering Progress with Reporting in Steadybit
30.04.2025With Reporting in Steadybit, teams can easily track their progress as they roll out new experiments and run tests across their organization. Measure how many issues have been discovered and fixed over time by running experiments.

Chaos Engineering for GKE Autopilot with Steadybit
16.04.2025By becoming an official partner for Google Autopilot, Steadybit is now able to integrate chaos engineering practices directly into your fully managed Kubernetes environments, using the same container-level fault injections as you would for any other standard cluster.

Level Up Your Monitoring: Splunk and Steadybit Join Forces
04.04.2025With Splunk Observability Cloud, you have the flexibility to define Detectors and SLOs tailored to your needs. As you set up your Detectors and SLOs in Splunk, wouldn't it be great to validate their behavior under chaos conditions? This is precisely where Steadybit steps in.

Why Now Is the Time to Combine Steadybit and PagerDuty for System Protection
18.02.2025The CrowdStrike outage in July 2024 exposed critical gaps in operational resilience, costing businesses billions and disrupting global operations. By integrating Steadybit’s chaos engineering with PagerDuty’s incident response, organizations can proactively test their systems and ensure teams are ready to handle disruptions before they escalate.

How Steadybit Enhances Chaos Engineering with AWS FIS
13.01.2025AWS Fault Injection Simulator (FIS) offers a solid foundation for chaos experiments in AWS environments, but its reach stops at AWS. Steadybit enhances this by supporting hybrid and multi-cloud setups, offering intuitive orchestration, custom experiment design, and enterprise-level features for deeper resilience testing across diverse infrastructures.

Enhancing Kafka Resilience with Steadybit’s New Extension
03.12.2024Apache Kafka is a cornerstone for building scalable event-driven systems, but its complexity can lead to cascading failures during disruptions. Steadybit's new Kafka extension empowers teams to simulate real-world scenarios, uncover vulnerabilities, and validate the resilience of their Kafka clusters under stress.

Cultivating a Culture of Resiliency Through Chaos Engineering
01.11.2024Building a culture of resiliency is as important as having a resilient system. Embracing Chaos Engineering at every level fosters a proactive, collaborative environment where failures turn into learning opportunities.

Why Site Reliability Engineers Must Embrace Chaos Engineering
22.10.2024Chaos Engineering involves introducing controlled disruptions into systems to identify vulnerabilities and improve overall resilience. Site Reliability Engineers (SREs) lead this process, focusing on monitoring, integrating chaos experiments into CI/CD pipelines, and ensuring experiments are carefully controlled and measured to avoid unintended real-world impacts.

5 Essential Chaos Engineering Experiments to Run Before Black Friday
11.10.2024When Black Friday hits, your system needs to be ready for anything. These five chaos engineering experiments will help you identify weak points and fortify your e-commerce infrastructure to handle the pressure of peak traffic.

Sync Chaos Engineering Templates with Ease
10.10.2024Knowledge sharing is key when implementing Chaos Engineering in your organization, and Steadybit's new experiment templates make this even simpler. This blog explores how to maintain synchronized experiment templates across multiple on-premise instances using hub connections and API-based methods.

Chaos Engineering: A Beginner's Guide
23.09.2024Chaos engineering strengthens your systems by proactively testing their resilience through controlled failures. It prepares your infrastructure for real-world challenges, ensuring reliability and uptime even under stress.

What is Chaos Engineering? The Ultimate Guide to Resiliency Testing
23.09.2024Chaos engineering strengthens systems by introducing controlled failures to expose weak points. As distributed systems grow more complex, this practice becomes essential to ensuring resilience and minimizing unplanned outages.

The Role of Chaos Engineering in Strengthening Enterprise Software
23.09.2024For large enterprises, reliability is everything. Whether you run an e-commerce platform or manage a Fortune 500 infrastructure, downtime impacts revenue and damages your reputation. Steadybit makes chaos engineering practical, running controlled experiments to push systems to their limits, so you can find weaknesses before they cause trouble.

5 Surprising Ways Small Teams Can Use Chaos Engineering to Enhance Software Resilience
23.09.2024Chaos engineering helps small teams proactively test and improve software resilience by simulating real-world failures. With Steadybit, you can automate experiments and continuously strengthen your system without overwhelming your team.

A Guide: The Art of Quick Application Startups
23.09.2024A fast application startup enhances user experience by reducing waiting times and minimizing downtime during deployments or failures. This guide explores strategies to achieve consistently quick startups.

Proactively Testing Alert Rules with Chaos Engineering: Integrating Grafana and Steadybit
23.09.2024Steadybit's new Grafana extension allows you to test alert rules using chaos engineering. This proactive approach ensures alerts are both reliable and resilient.

5 Key Ethics Principles of Chaos Engineering: What You Need to Know
10.09.2024Chaos engineering is a powerful tool to uncover system vulnerabilities, but it requires ethical practices to protect user trust and data privacy. This article breaks down five essential principles for implementing chaos engineering responsibly, offering practical steps to safeguard system integrity and transparency.

The Ultimate Guide to Reliable Services in an Unreliable World
06.09.2024Microservices and APIs bring flexibility but also create hidden challenges, especially around service dependencies. Discover how to manage these dependencies effectively and prevent performance issues before they impact your users.

Standardizing Resiliency on Kubernetes
01.09.2024Kubernetes resilience goes beyond technology—it's about ensuring your services can handle anything without missing a beat. Learn how to safeguard your deployments and minimize downtime.

Introducing Steadybit's Experiment Templates
11.08.2024Introducing Steadybit’s Experiment Templates—customizable, reusable tools that simplify chaos experiments and save time. Focus on improving system reliability, not setup.

Blast Radius and Access Control: Strategies for a Safer System
06.08.2024Strong access control is essential for running chaos experiments without disrupting critical systems. Steadybit’s Role-Based Access Control ensures tests stay focused and controlled.

How to Reduce Cloud Costs with Chaos Engineering
05.07.2024Balancing cloud costs with system reliability is a challenge. Discover how chaos engineering can optimize your cloud environment, saving costs and improving performance.

Embracing Digital Resilience: Navigating the Implications of the Digital Operational Resilience Act (DORA)
23.04.2024DORA is set to reshape digital risk management by 2025, with a focus on resilience testing. Learn how Steadybit’s platform can help you meet DORA’s requirements and build stronger systems.

Steadybit Joins Forces with LoadRunner Enterprise
10.04.2024Big news: Steadybit now integrates with LoadRunner Enterprise, pushing the boundaries of chaos and performance testing. Together, we're creating more resilient digital environments.

Types of Chaos Experiments (+ How To Run Them According to Pros)
10.04.2024Steadybit empowers you to run chaos experiments like dependency failures, resource manipulation, and network disruption. Discover how to simulate these real-world conditions to enhance system resilience.

Meet Advice: Your New Chaos Engineering Sidekick
05.03.2024Meet Advice, Steadybit’s newest tool for navigating chaos engineering. It’s customizable, open-source, and always ready to help you fine-tune your system’s reliability.

How Chaos Engineering Uncovers The Human Factor in Resilience
17.01.2024Chaos engineering not only strengthens systems but also equips teams to handle failures with confidence. By simulating real-world disruptions, it prepares both technology and the people behind it for the unexpected.

Top 5 Reasons Companies Should Adopt Chaos Engineering in 2024
22.12.2023This blog is about why chaos engineering is your go-to move in 2024. It's not just about keeping up with tech trends; it's about building systems tough enough to roll with the punches. Let's dive into how chaos engineering can be your company's ticket to staying resilient and reliable when things get shaky.

Enhance Kubernetes Reliability with Steadybit's Latest Features
15.12.2023Reliability is the cornerstone of user satisfaction in today's world. At Steadybit, we understand the critical nature of this reliability, especially in Kubernetes clusters widely adopted across organizations. We're excited to announce our latest suite of enhancements, designed to empower users to detect and remediate potential risks in their Kubernetes environments proactively.

Why Chaos Engineering is Essential for Engineering Leaders Ready To Scale with Confidence
24.11.2023Scalability is a crucial concern for any engineering team. As your operations grow, so does the complexity of your systems. How can you ensure robustness and reliability during this vital phase? The answer is Chaos Engineering. This blog delves into why this methodology is a game-changer for engineering leaders guiding their teams through scale.

The Power of Collaboration with Steadybit's Open-Source Chaos Engineering Attacks
24.11.2023We're taking an exciting step into the world of open-source software. The code for Steadybit's Chaos Engineering attacks is now publicly available, offering a new level of transparency and collaboration. But what does this mean for developers and the broader community? Let's delve in.
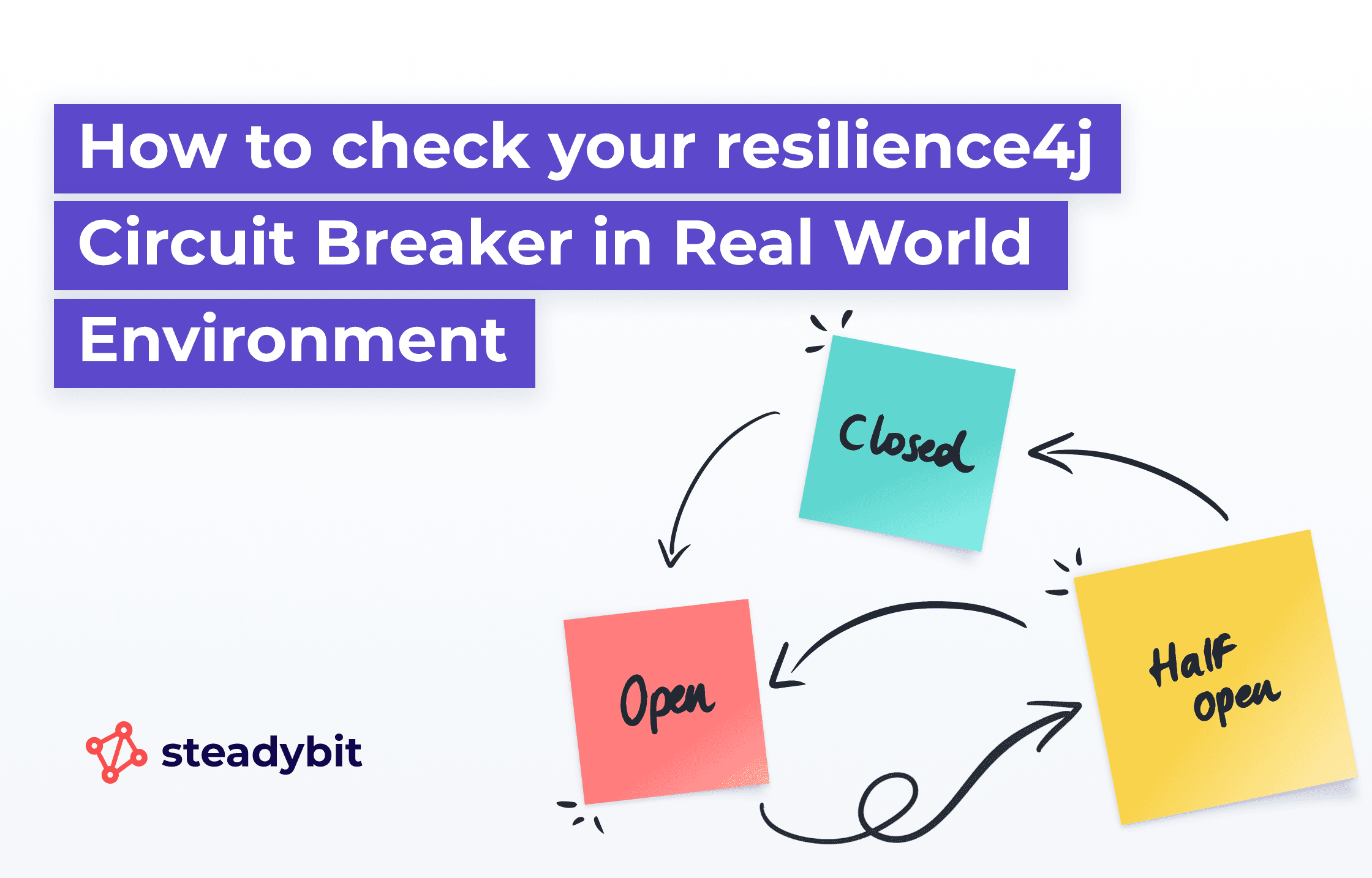
How to check your resilience4j Circuit Breaker in Real World Environment
15.11.2023Two years have passed since my first blog post about Retries with resilience4j, where I promised a second post about Circuit Breakers. There it is!

The Evolution and Implementation of Chaos Engineering
15.11.2023Chaos Engineering helps businesses ensure system resilience by intentionally introducing failures and observing how systems respond. Learn how tools like Steadybit simplify this process for continuous improvement.

Why Chaos Engineering is a Must for E-Commerce This Holiday Season
10.11.2023The holiday season is a high-stakes period for e-commerce businesses, with traffic and sales often surging to yearly highs. While this presents a significant revenue opportunity, it also puts your systems under immense strain. In this environment, preparing with Chaos Engineering is not just an advantage; it's a necessity. Here's why.

Navigating Chaos Engineering: An Actionable Guide for New Practitioners
16.10.2023In this blog post, we'll take a look at how your team can effectively incorporate Chaos Engineering principles into your organization using the Steadybit platform.

Driving Business Value with Chaos Engineering: A Decision Maker's Guide
05.10.2023By utilizing Steadybit for Chaos Engineering, you not only improve the reliability of your system but also enhance your business's financial resilience and overall success.

Launching Explorer - The Companion of Your Chaos Engineering Journey
23.09.2023Improving your system's reliability can be challenging. Initially, you are looking at a large pile of infrastructure components from a dozen teams. They are all somehow connected, and every piece will fail eventually. While you can use Chaos Engineering to reveal the impact of each failure, you can't predict when a failure will happen. This makes it hard to know where to start and where to continue to keep getting the most value from Chaos Engineering. Also, once you have identified the first findings with Chaos Engineering, you need to check what other components suffer from similar issues.

Unveiling Experiment Schedules: Streamlining Workflows Like Never Before
16.09.2023We’re excited to introduce Experiment Schedules, designed for simplicity and flexibility to revolutionize how you manage experimental workflows.

Unpacking Resilience Engineering with Steadybit’s Co-Founder and CEO, Benjamin Wilms, on the SMC Journal Podcast
21.08.2023We're super excited to share some insights from a recent episode of the SMC Journal podcast featuring none other than our co-founder and CEO, Benjamin Wilms. A deep dive into the realm of performance engineering, this episode unpacks the world of resilience testing, chaos engineering, and, of course, the role Steadybit is playing in all this.

Unleashing the Power of Chaos Engineering with Steadybit: Insights from Manuel Gerding
10.08.2023In our most recent webinar, Tailor Chaos Engineering to Scale Your Reliability Journey, our Product Manager Manuel Gerding, discussed how chaos engineering can enhance a system's reliability. The session featured riveting insights on ways to conduct chaos engineering more effortlessly, while demonstrating Steadybit's robust approach to this practice.

Why You Shouldn't Fear Chaos Engineering: A New Approach to Ensuring System Resilience
06.08.2023Discover chaos engineering’s benefits by introducing controlled failures to reveal system weaknesses. This approach improves resilience, identifies vulnerabilities, and promotes continuous improvement for robust systems.

Boost your GitOps practices by integrating Chaos Engineering with Steadybit
19.07.2023Learn how to integrate Chaos Engineering into your GitOps practices using Steadybit. We'll shortly cover in this blog post what GitOps is, followed by where you can benefit from integrating Chaos Engineering. Finally, we integrate Chaos Engineering hands-on using the Steadybit CLI and a GitHub action.

Painting Chaos: how our new colour scheme is taking Chaos Engineering to the next level
17.05.2023Why purple and blue are the new green and yellow: learn how colours have the power to influence our perceptions and emotions, and how the wrong colour can make or break a product. Let's channel our inner Bob Ross and paint some chaos together and see how this small change can make a big difference in the resilience of our systems.

How-to: AWS Lambda Functions Failure Injection with Steadybit
05.04.2023This article demonstrates how to implement an attack to inject failures for AWS Lambda and integrate it into Steadybit.

AWS Lambda Functions Chaos Engineering - Extending Steadybit - Part 3
30.03.2023This article demonstrates how to implement an attack to inject failures for AWS Lambda and integrate it into Steadybit.

AWS Lambda Functions Chaos Engineering - Extending Steadybit - Part 2 - Discovery
30.03.2023This article demonstrates how to implement a discovery for AWS Lambda. This is a prerequisite to inject failures into those.

Steadybit Integration Now Live in Datadog Dashboard
22.02.2023We have released our integration into Datadog recently. Within Datadog, the Steadybit integration is now available and can be installed. The integration includes a ready-to-go dashboard. Steadybit experiment events can also be inspected in the Datadog event views.

Extend Steadybit: Custom Extensions and Integration Guide (Part One)
16.02.2023You can extend Steadybit to make it a perfect match for your systems. We already provide some OSS extensions. This article will give you an overview of the available extension points.

The State of Chaos Engineering
11.01.2023Chaos Engineering has been around for several years, and the practice has evolved. Within this post, we will look at past and modern interpretations, industry opinions and what we believe to be critical for you to leverage the practice to reach your goals.

Behind the Scenes: Query Language Editor
24.10.2022The last blog post taught you how to set up a query language lexer and parser using ANTLR. This post will cover making this setup accessible in a user interface.

Behind the Scenes: Query Language Parsing
14.10.2022In this second part of the query language blog series, we look closely at the implementation of the lexer and parser.

Continuous Verification with Steadybit: Boost Resilience
10.10.2022This article will look closely at continuous verification with Steadybit through resilience testing and how it helped us internally.

Use Steadybit's Query Language to enhance your experiments
30.09.2022When managing complex environments it's important to have powerful tools available to keep control. Now, Steadybit enhances the way how to filter targets by introducing the Query Language.

How to build reliable systems under unpredictable conditions
03.09.2022Steadybit wants to change the way outages are handled. Instead of reacting, Steadybit strives for a proactive approach integrated into the development cycle of modern applications.

Shift Left: Empower Developers with Chaos Engineering
04.05.2022If you are also wondering how to shift left Resilience and Chaos Engineering to Developers, you are reading the right article.

Chaos Engineering with k6 and Steadybit - There’s more than Performance Testing
19.04.2022Since we build software nowadays differently than a couple of years ago, performance testing alone isn't sufficient anymore. Learn how to profit from the synergy of performance testing and Chaos Engineering - a symbiosis of k6 and Steadybit.

See metrics of your chaos experiments in Steadybit with Instana
14.03.2022If you run chaos experiments, you certainly want to see how these experiments play out in your monitoring tools - even more so when you run experiments.

Declaring Resilience Expectations
28.02.2022Is chaos engineering for experts only? No! Learn how we imagine opening up chaos and resilience engineering to wider audiences through declared and reusable expectations!

Who Needs GameDays? Resilience Testing using Testcontainers
22.02.2022Writing resilience tests with the Steadybit Testcontainers library makes it easy to validate and strengthen the fault tolerance of your application in a controlled environment. While these tests effectively prevent regressions and catch issues early, they complement rather than replace Chaos Engineering GameDays, which help teams rehearse and respond to complex, real-world incidents across distributed systems.

Validate your Kubernetes Resource Limits with Chaos Engineering
08.02.2022Validating resource limits in Kubernetes is crucial to ensuring that your applications behave as expected under load and do not impact other pods on the same node. Steadybit provides the ability to simulate increased resource usage, allowing teams to verify and fine-tune these limits for improved resilience and stability.

Simulate DNS Outages with Steadybit
24.12.2021Testing DNS failures with tools like Steadybit helps identify vulnerabilities in how applications handle DNS disruptions. This proactive approach ensures systems remain resilient, even when DNS services are compromised.

How to run a Chaos Engineering GameDay
24.12.2021A GameDay is a structured, collaborative exercise where teams test their systems for weaknesses in a safe, exploratory environment, aiming to improve resilience. These exercises reveal hidden knowledge within the team and identify critical weak points. Running GameDays regularly ensures ongoing system reliability and boosts confidence. From crafting meaningful experiments to executing them with minimal preparation, teams gain valuable insights and create more resilient systems over time.

Retries with resilience4j and how to check in your Real World Environment
24.12.2021Resilience4j is a powerful tool for building fault-tolerant applications. This post explores how to implement and test its retry mechanism, demonstrating the benefits of fallback methods and showing how to evaluate real-world performance impacts using Steadybit to ensure reliability under load.

How to See Metrics of Your Chaos Experiments in Steadybit With New Relic
24.12.2021Integrating New Relic with Steadybit allows you to monitor and verify the impact of your chaos experiments in real-time, directly within your existing observability setup. This post walks you through configuring the "State Check (via REST API)" feature so you can track New Relic events during experiments, enhancing control and insight into your system's response.

The Evolution of Chaos Engineering
24.12.2021Chaos Engineering has evolved from a radical practice to an essential part of building resilient systems. While breaking parts of a system is simple, creating a culture of resilience requires collaborative efforts, continuous learning, and tools that guide teams in assessing risks without hindering progress. The future lies in balancing reliability with development speed and fostering shared knowledge to build transparent, resilient applications.

How to validate your Kubernetes Liveness Probes with Chaos Engineering
24.12.2021Liveness probes are vital for ensuring that applications recover automatically when they enter an unhealthy state. This post explains how to set up liveness probes in Kubernetes and use Steadybit to verify their effectiveness through controlled experiments that simulate delays and observe pod restarts, confirming the reliability of these probes.

How Healthy Is The Tech Industry? An Interview With Nora Jones – Founder and CEO of Jeli.io
24.12.2021This post delves into how mental health and team resilience are pivotal for fostering a culture of reliability in tech, especially in Chaos Engineering. Insights from Nora Jones, CEO of Jeli.io, emphasize that building resilient systems goes beyond technical tools—it requires psychological safety, effective communication, and allowing teams to learn and share knowledge collaboratively.

Harden Performance of REST calls using Spring WebFlux
24.12.2021If you have sequential REST calls in your code, how do they behave under slow network conditions? This post demonstrates how to enhance performance by switching to Spring WebFlux for parallel data fetching and validate improvements with Steadybit experiments.

Track Your Chaos Experiment Metrics in Steadybit Using Prometheus
24.12.2021Integrating Prometheus with Steadybit allows you to track real-time metrics during chaos experiments for better insights and control. This post explains how to set up Prometheus as a monitoring integration, configure state checks, and observe alerts directly in Steadybit to enhance your experiments’ effectiveness.

How to Measure Chaos Engineering
24.12.2021Measuring the steady state of your system is essential for effective Chaos Engineering. This blog post outlines how to assess system resilience through static analysis, dynamic testing, and defining critical metrics. With a user-focused approach, leveraging metrics like response time and business indicators, teams can better understand system health, detect issues faster, and enhance MTTR for greater reliability.
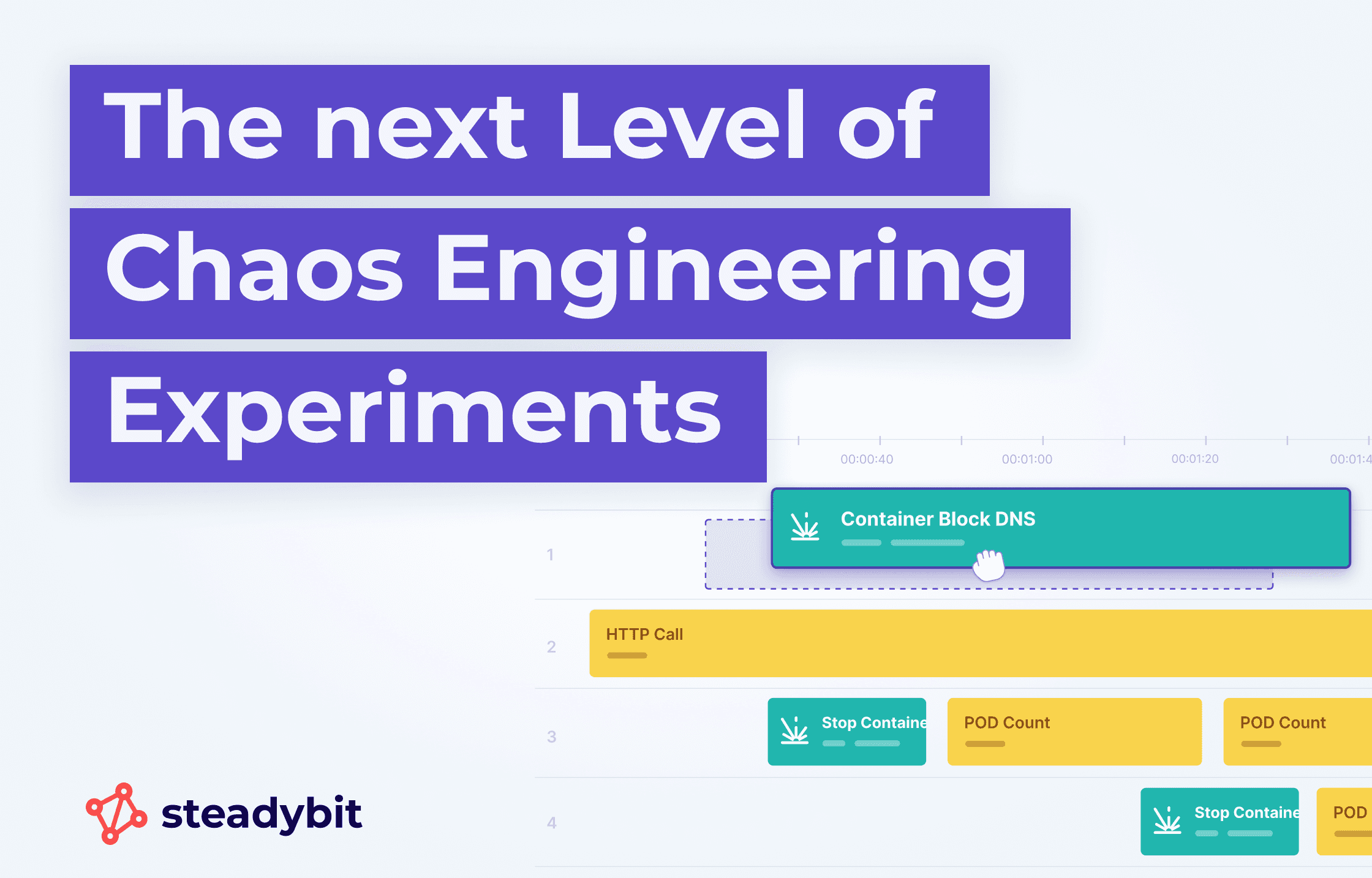
Elevating Chaos Engineering Experiments to the Next Level
23.12.2021Distributed systems are complex, and Steadybit’s new experiment engine helps test realistic scenarios like DNS failures or container restarts under turbulent conditions. This blog post shows how to set up comprehensive experiments that mimic real incidents to uncover system weaknesses and explore solutions for improved resilience.

Is Chaos Engineering Worth It? A Cost-Benefit Analysis Guide
22.12.2021Downtime is costly, and Chaos Engineering helps mitigate these risks by exposing weaknesses before they become issues. This post breaks down the cost-benefit analysis of implementing Chaos Engineering, emphasizing that while initial costs and potential disruptions exist, the long-term ROI—like a 92% return in a sample calculation—proves its value for improving system resilience.

A Common Pitfall of Spring Boot's RestTemplate
21.12.2021Spring Boot’s RestTemplateBuilder defaults can sometimes overlook critical timeout settings, leading to potential reliability issues under network strain. This post explains how to identify and address such gaps using Steadybit for chaos testing, demonstrating how to configure appropriate timeouts to enhance your application’s robustness.

Problem first: User Centricity at Steadybit
20.12.2021Building a successful, user-centric product is crucial for a startup like Steadybit. This post discusses Steadybit’s journey from its founding vision to refining its product by prioritizing user research, understanding pain points, and balancing engineering speed with system reliability.

Top 3 Kubernetes Weak Spots affecting your Availability
19.12.2021This post covers the top three weak points in Kubernetes that can impact service availability: single pod replica counts, missing liveness and readiness probes, and missing resource limits. By using Chaos Engineering, you can simulate turbulent conditions to ensure your cluster can handle real-world failures effectively.

Testing Exception Handling of Spring's REST Controllers
18.12.2021Test whether your exception handling for Spring Boot’s RestTemplate is effective using chaos experiments with Steadybit. This method eliminates the need for cumbersome mock testing or manual interventions.

How to Survive an AWS Zone Outage
17.12.2021Cloud services like AWS, Azure, and GCP enable rapid software deployment with on-demand resources that can be more cost-effective than traditional data centers. However, designing for resilience requires understanding key concepts like regions and availability zones, which help applications withstand failures through distributed and isolated infrastructures.

Verify Your Startup Times To Avoid Surprises
16.12.2021Fast application startup times are crucial for maintaining a low mean time to recovery (MTTR) and supporting continuous deployment without fixed maintenance windows. This post explains how to validate startup performance through automated chaos experiments that ensure new instances become ready within a set timeframe, enhancing reliability and operational predictability.