How to Reduce Cloud Costs with Chaos Engineering

Numerous organizations face a vital problem when they need to handle cloud expenses without compromising system reliability. Through its intentional disruption of systems chaos engineering enables organizations to achieve better cost efficiency in cloud environments. This article examines how to apply chaos engineering for cloud cost reduction through the analysis of three specialized articles.
Chaos engineering provides organizations with important advantages for their business operations.
Chaos engineering represents an intentional system disruption method which helps businesses identify vulnerabilities to stop major outages before they occur. The main difficulty in evaluating its advantages stems from determining the expenses related to prevented system failures. The actual value reaches further than basic prevention capabilities. Organizations can prevent major expenses and lost opportunities through early bug detection and resolution during the development phase.
- Baseline Metrics and Costs:
Start by measuring your current performance indicators such as mean time to detection (MTTD) and mean time to resolution (MTTR) and record both high-severity incidents and infrastructure metrics that include resource utilization and latency. The economic cost of previous incidents allows you to determine the cost savings from implementing chaos engineering. - Tracking Issues:
Enter every problem discovered through chaos testing into your ticketing system’s database. The documentation enables managers to demonstrate chaos engineering success through visible numbers of resolved issues.
Managed Clusters and Cost Optimization
Managed Kubernetes clusters provide a pricing system based on usage but this model creates unexpected costs unless properly managed. Through chaos engineering organizations can achieve cost reduction in their managed clusters by following these steps:
- Capacity Planning and Right-Sizing:
The cluster size represents the main element that determines your expenses. Start by examining your current CPU, RAM and disk space utilization to identify your essential capacity needs. Your nodes must survive stress tests through chaos engineering to verify their ability to operate under resource limitations. The process helps you determine whether reducing your node sizes to cheaper models will affect system performance. - Autoscaling Validation:
The process of chaos engineering helps users generate high resource usage that activates their autoscaling rules to verify their proper operation. The approach enables organizations to strike the perfect equilibrium between system performance and cost expenses. - Utilizing Preemptible Instances:
The cost benefits of preemptible instances come with the drawback that these instances may stop running at any moment. The testing process of chaos engineering includes simulating random instance terminations to verify that applications maintain operational stability even when instances get terminated. Organizations that master preemptible instance usage can achieve up to 90% cost savings for their cloud expenses.
Cost-Benefit Analysis of Chaos Engineering
The calculation of chaos engineering return on investment requires a comparison between the expenses of possible outages versus the costs of running chaos engineering practices. A basic calculation method demonstrates the advantages in the following way:
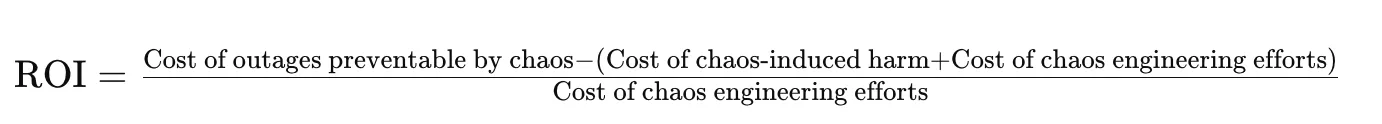
For instance, if preventable outages cost $500,000 but chaos-induced harm amounts to $10,000 and chaos engineering costs $250,000, then the return on investment calculation would be:
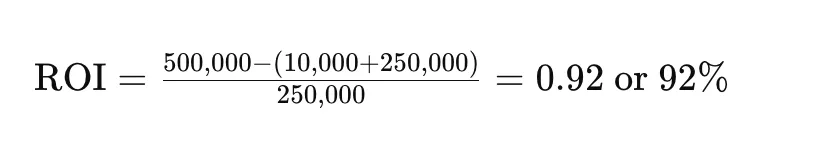
The invested capital for chaos engineering delivers a 92% return on investment thus demonstrating high profitability to support the investment costs.
Implementing Chaos Engineering
- Technical Tooling: Use available tools to execute chaos experiments which involve slowing down CPU usage and disrupting network traffic. The implementation requires suitable infrastructure to both run and study the outcomes of these experiments.
- Collaboration and Documentation: Involving your teams during chaos engineering activities is essential. Create experimental plans while notifying appropriate teams about their involvement then carefully document all encountered problems and success rates to achieve ongoing improvement.
- Vendor Solutions: The platform Steadybit enables organizations to simplify chaos engineering operations through its toolset and frameworks thus making it possible to avoid building a dedicated chaos engineering team.
Wrapping Up
Your systems need chaos engineering to understand their resilience while you optimize costs. When you integrate chaos engineering into your cloud strategy you will achieve substantial cost savings and enhance system reliability and develop infrastructure which can deal with unanticipated disruptions.

Get started today
Full access to the Steadybit Chaos Engineering platform.
Available as SaaS and On-Premises!
or sign up with

Book a Demo
Let us guide you through a personalized demo to kick-start your Chaos Engineering efforts and build more reliable systems for your business!