How to check your resilience4j Circuit Breaker in Real World Environment
Two years have passed since my first blog post about Retries with Resilience4j, where I promised a second post about Circuit Breakers. Here it is!
Recap and the problem
In our previous blog post, we added retries to our shopping-demo. The gateway application will retry failing requests to one of the product microservices up to three times and provide a fallback value if the third retry isn’t successful.

Adding the retries increased the overall reliability of the gateway. For example, users get hot-deals if there’s a minor hiccup, and the service can respond on a second try. Thanks to the fallback value, users can get products from the other categories if the hot-deals microservice does not respond successfully during the retries.
However, this could lead to a follow-up problem. Imagine you are feeling bad and want to stay in bed that day. Now all your colleagues are asking you the whole day: “Are you feeling better?”, “Are you feeling better?” “Are you….” It’s not the best situation to recover.
The same situation could happen to a microservice that is having some troubles. It could just be restarting. Due to the retries, the microservice receives way more requests- at least three times more. And you also know your user. Quickly hitting F5 is still the best option to recover from any problems. So, the load could heavily increase in turbulent situations, reinforcing the problems. Martin Fowler calls it a “catastrophic cascade“.
Introducing a Circuit Breaker
This is where the concept of circuit breaker makes sense. I couldn’t explain it better than Martin Fowler did in his article about circuit breakers.
“The basic idea behind the circuit breaker is straightforward. You wrap a protected function call in a circuit breaker object, which monitors for failures. Once the failures reach a certain threshold, the circuit breaker trips, and all further calls to the circuit breaker return with an error without the protected call being made at all. ”
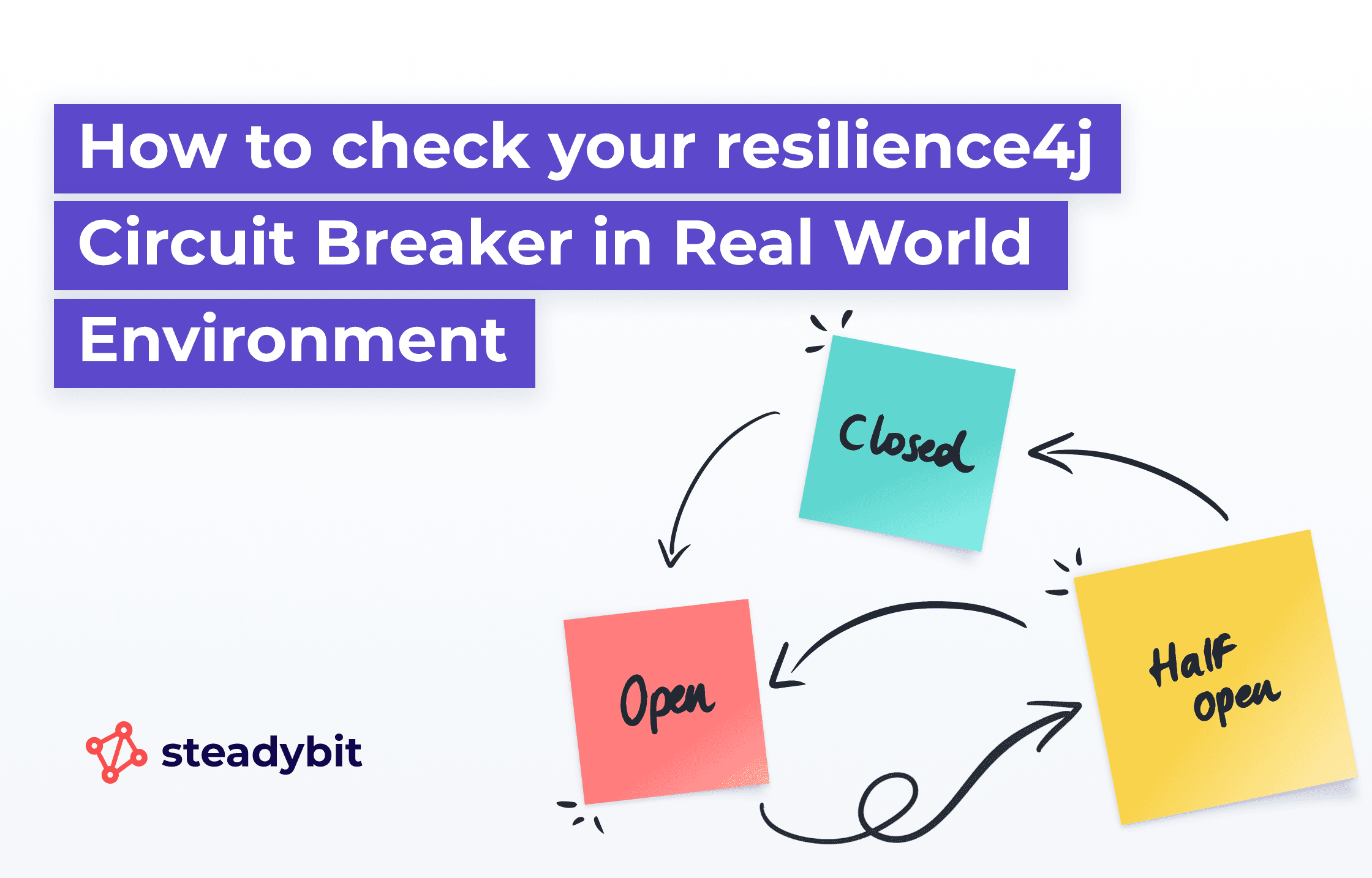
A circuit breaker has three states.
CLOSED: Everything is working as expected; no problems, and calls to the protected remote system are made.OPEN: The configured error threshold has been reached. No calls to the protected remote system are made until a given duration has elapsed.HALF_OPEN: In this state, a few requests to the remote system are allowed to test whether the system is responding again and if the circuit breaker can be closed.
You can look at the configuration options of the circuit breaker implementation in resilience4j to better understand how a circuit breaker’s behavior can be fine-tuned.
How to Add a Circuit Breaker with Resilience4j
To add a circuit breaker, we use another Resilience4j annotation, @CircuitBreaker next to our @Retry -Annotation from our previous blog.
@Retry(name = "fashion", fallbackMethod = "getProductsFallbackRetry")
@CircuitBreaker(name = "fashion", fallbackMethod = "getProductsFallbackCircuitBreaker")
public List<Product> getFashionWithRetryAndCircuitBreaker() {
…
}
Next, we add some configuration as we don’t want to use the defaults for the circuit breaker in our case:
resilience4j: circuitbreaker: instances: fashion: registerHealthIndicator: true slidingWindowType: COUNT_BASED slidingWindowSize: 100 minimumNumberOfCalls: 10 waitDurationInOpenState: 10000
Ready to Test
Same story as in the previous blog post. You could write an integration test, for example, using @SpringBootTest. An example of circuit breakers can be found here. But again, wouldn’t it be nice to see the effects in your real-world environment?
Let’s use Steadybit to have a closer look and implement a nice experiment.
Our Hypothesis
As good chaos engineers, we always start with a hypothesis for an experiment. What would we expect?
- The HTTP-Check should start with regular, fast response times
- The Circuit-Breaker State is
CLOSED - As soon as a microservice has problems, I would expect the exact “stepped” response times from the experiment for the “Retry”-Blog-Post. We used a failure rate of 50% in this experiment. I quote myself: “You can see three shapes of response times, some around zero milliseconds, some around 500 milliseconds, and some around one second. That’s the impact of the 500 milliseconds wait duration between the retry calls.”

- The Circuit-Breaker State is
OPENafter the attack - Response Times shouldn’t show any steps any longer cause the fallback of the
OPENCircuit-Breaker is used. - After a while, the Circuit-Breaker is
CLOSEDagain.
Designing the Chaos Experiment

Lane 1
- The gateway is deployed in Kubernetes with a replica count of 2. We want to focus on the behavior of the circuit breaker in a single gateway pod. That’s why we scale down the deployment to 1.
Lane 2
- Continuously check the results of the gateway-api http endpoint.
Lane 3
- We have configured Resilience4j to publish information about the state of the circuit breaker in Spring Boot health endpoint.
registerHealthIndicator: true. We are using HTTP checks to check the state of the circuit breaker.1. Check if the state isCLOSED2. Start a controller exception attack targeting the hot-deals microservice for 15 seconds3. Check if the state isOPEN4. Wait 20 seconds5. Check if the state is back to
CLOSED
Reviewing the Experiment Results

Great! The experiment ran successfully without any errors. The three checks for the states of the circuit breaker succeeded. All requests to the gateway endpoint have been answered within a reasonable time.
But wait – Didn’t I expect the “stepped” response times as we had with the retries? At least as long as the circuit breaker is in OPEN state. We need help seeing steps in our response time. I expected that the @Retry would be handled first, and after that, the @CircuitBreaker would add its magic. A closer look into the Resilience4j documentation confirms what our experiment was showing.
The Resilience4j Aspects order is the following:
Retry ( CircuitBreaker ( RateLimiter ( TimeLimiter ( Bulkhead ( Function ) ) ) ) )
This way, the Retry is applied at the end (if needed).
So the Circuit-Breaker is returning its fallback and the Retry is no longer being used with our configuration. We need to change the circuitBreakerAspectOrder and the retryAspectOrder to have the Retry before the CircuitBreaker.
Conclusion
Conducting chaos experiments yields a wealth of insights about your system. In addition to improving reliability, this is a pivotal aspect when utilizing our solution. Fresh discoveries are perpetually on the horizon, as software often exhibits behavior distinct from our expectations. In intricate systems, integrated testing is an indispensable practice.
If you want to get started with Steadybit to run your own experiments, you can sign up for a free trial or request a demo.
FAQs (Frequently Asked Questions)
What is the purpose of adding a circuit breaker in our system?
The circuit breaker is introduced to enhance resilience in our application by preventing cascading failures. It allows the system to gracefully handle errors and maintain functionality even when certain components are under stress.
How do we implement a circuit breaker using resilience4j?
To implement a circuit breaker with resilience4j, we utilize specific annotations provided by the library. This allows us to define the behavior of the circuit breaker, such as thresholds for failure rates and recovery time.
What should I expect when testing the circuit breaker?
When testing the circuit breaker, you can expect to simulate various failure scenarios to observe how the system reacts. The goal is to ensure that the circuit breaker correctly prevents requests from going to failing services and provides useful insights during failures.
What is the significance of forming a hypothesis in chaos engineering?
Forming a hypothesis is crucial as it sets a clear expectation for what we believe will happen during chaos experiments. It helps guide our tests and allows us to measure outcomes against our initial assumptions, ultimately improving our understanding of system behavior.
Can you describe the experiment design mentioned in the blog post?
The experiment design involves deploying a gateway in Kubernetes with a replica configuration. This setup allows us to test how well our circuit breaker functions under load and failure conditions, ensuring that it can handle real-world scenarios effectively.
What were the results of the chaos experiment conducted?
The experiment ran successfully without any errors, indicating that our implementation of the circuit breaker worked as intended. This success reinforces our confidence in using chaos engineering practices to improve system resilience.

Get started today
Full access to the Steadybit Chaos Engineering platform.
Available as SaaS and On-Premises!
or sign up with

Book a Demo
Let us guide you through a personalized demo to kick-start your Chaos Engineering efforts and build more reliable systems for your business!