How to Check Kafka Consumer's Reaction to Record Loss

Apache Kafka is a key technology in modern data streaming, enabling systems to handle and transit massive volumes of data. Kafka consumers are applications that subscribe to topics in an Apache Kafka cluster to read and process data records. As endpoints of Kafka’s publish-subscribe model, they retrieve messages published by producers.
But what happens when things go wrong?
For Kafka consumers, record loss can be a critical failure point, leading to data inconsistencies and significant business impact. The only way to ensure your systems are resilient is to proactively test how your consumers behave when faced with this exact scenario.
In this guide, we will walk through how to design and run an experiment to check your Kafka consumer’s reaction to record loss. We’ll show you how to simulate this failure safely, monitor the results, and gain confidence in your system’s reliability using chaos engineering.
What is Record Loss in Kafka?
Record loss occurs when a consumer fails to process messages that have been produced to a topic. This isn’t just a theoretical problem; it can happen in several ways in a production environment.
The most common causes include:
- Authorization Issues: A consumer might suddenly lose permission to access a specific topic, preventing it from fetching new records.
- Offset Mismanagement: Incorrect handling of consumer offsets can cause the consumer to “jump” over a batch of records, effectively losing them.
- Intentional Deletions: An administrator might delete records from a partition, for example, to comply with data retention policies, while a consumer is temporarily offline.
The impact of even a small amount of record loss can be severe. It can corrupt downstream data, break application logic, and lead to poor user experiences. That’s why verifying your consumer’s resilience is not just a best practice—it’s essential for operational readiness.
Testing Kafka Resilience with Chaos Engineering
To effectively test your Kafka consumer, you need to run meaningful tests on your system. Instead of waiting for issues to occur in Production, you can run experiments to proactively observe how your systems respond to record loss issues.
For this guide, we’ll build our experiment using Steadybit, the chaos engineering platform that makes it easy to reveal reliability gaps and design experiments fast.
Before you begin, you will need:
- An active Kafka cluster and a consumer application.
- Access to the Steadybit platform.
You can use the open source Kafka extension to connect Steadybit with your Kafka cluster and start running valuable experiments in minutes.
Designing a Kafka Experiment to Simulate Record Loss
Our experiment should realistically mimic the conditions that lead to record loss. The goal is to see how the consumer application responds when records disappear from a topic partition between fetches.
You could start with hypothesis like:
“Simulate the loss of records to see how the consumer recovers. We should look at the logs of the consumer after the deny to see that it begins to consume records with value corresponding only to the last records after the delete.”
Then, these are the key actions to orchestrate this use case:
- Deny Topic Access: We’ll start by temporarily blocking the consumer’s access to the topic. This simulates a permission issue and pauses consumption.
- Produce Messages: While the consumer is blocked, we will continue to produce messages to the topic to simulate a live environment.
- Delete Records & Adjust Offset: This is the core of the attack. We will delete the newly produced records and manipulate the partition’s offset to make it seem as if the records never existed.
- Restore Access: Lastly, we’ll restore the consumer’s access and observe its behavior.
This sequence creates a scenario where the consumer, upon reconnecting, is faced with a gap in the message log. By seeing how it handles this gap, you can identify potential performance issues.
This pre-built experiment template from Steadybit’s Reliability Hub shows what that would look like:
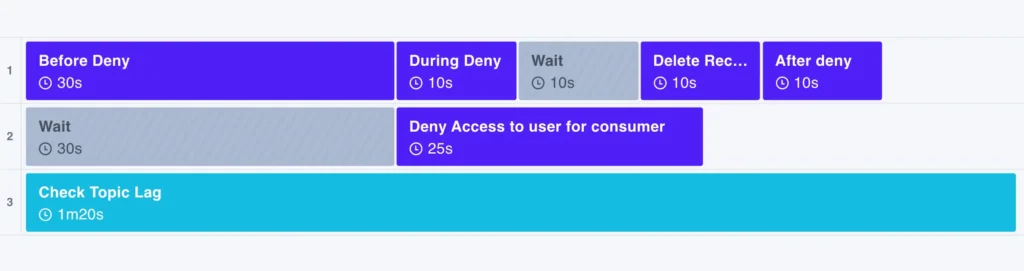
Steadybit Experiment Template: Check Kafka Consumer’s Reaction to Record Loss
This experiment creates a scenario where the consumer, upon reconnecting, is faced with a gap in the message log. By running it, we can see how the consumer handles this gap.
Reviewing the Results and Consumer Reactions
With the experiment running, your focus shifts to observation. In a chaos engineering tool like Steadybit, you’ll be able to watch as each step executes and see how your application responds.
When it is complete, check your application’s logs for any errors or warnings related to authorization failures or offset problems. You can also monitor the consumer lag for your topic. This metric shows the difference between the latest offset on the topic partition and the offset your consumer has committed. A sudden drop or unusual fluctuation in lag can indicate that the consumer has skipped records.
If the consumer logs show that after the deny, the consumer began to consume records with values corresponding only to the last records after the delete, then your experiment was a success and you have a resilient consumer.
A resilient consumer detects the offset jump, logs a critical error, and either shuts down safely or triggers an alert for manual intervention. It would not silently continue processing from the new offset, which would hide the data loss.
If your experiment reveals that you have a vulnerable consumer, you have a clear action item: improve your consumer’s error-handling logic. This could involve adding checks for offset continuity or implementing more robust monitoring and alerting around consumer lag.
Getting Started Running Kafka Reliability Tests
Waiting for a production incident to discover a weakness in your Kafka consumers is risky and reactive. By proactively testing for scenarios like record loss, you can identify and fix issues before they impact your customers. Chaos engineering is the best practice for building this type of operational resilience.
Ready to find out how your Kafka consumers stand up to pressure?
You can get started with a 30-day free trial of Steadybit or book a demo for your team today.

Get started today
Full access to the Steadybit Chaos Engineering platform.
Available as SaaS and On-Premises!
or sign up with

Book a Demo
Let us guide you through a personalized demo to kick-start your Chaos Engineering efforts and build more reliable systems for your business!