Enhancing Kafka Resilience with Steadybit’s New Extension

Apache Kafka is an indispensable tool for building scalable and resilient event-driven systems. However, its architecture can introduce complexity, and disruptions—whether within Kafka itself (like a broker failure) or from external producers or consumers—can cascade, creating significant challenges.
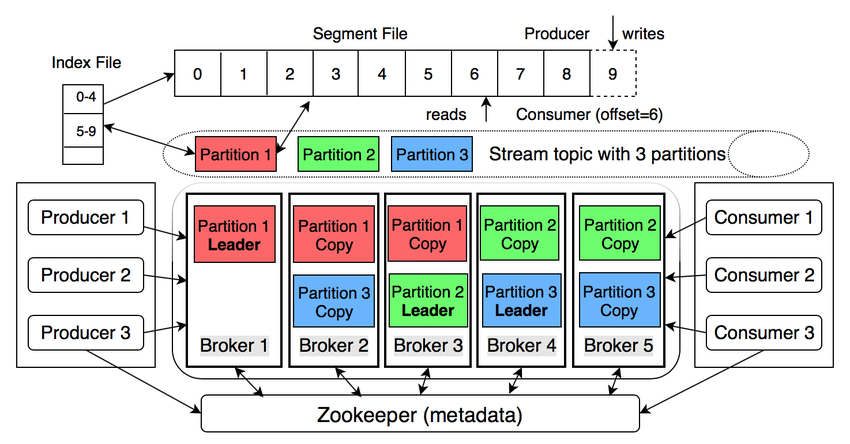
Source: Kafka Architecture Illustrated
When multiple producers and consumers are interconnected to meet business needs, even a slight topic lag can propagate through the chain, much like a traffic jam during rush hour. This “butterfly effect” can slow down processes across the board. A considerable lag can paralyze business operations, making it essential to understand how such scenarios unfold and how to address them.
At Steadybit, we believe that injecting chaos into Kafka systems in a controlled manner yields critical insights into system behavior under stress. This philosophy led us to develop and release a powerful new extension designed to push the boundaries of chaos engineering for Kafka.
Introducing the New Kafka Extension
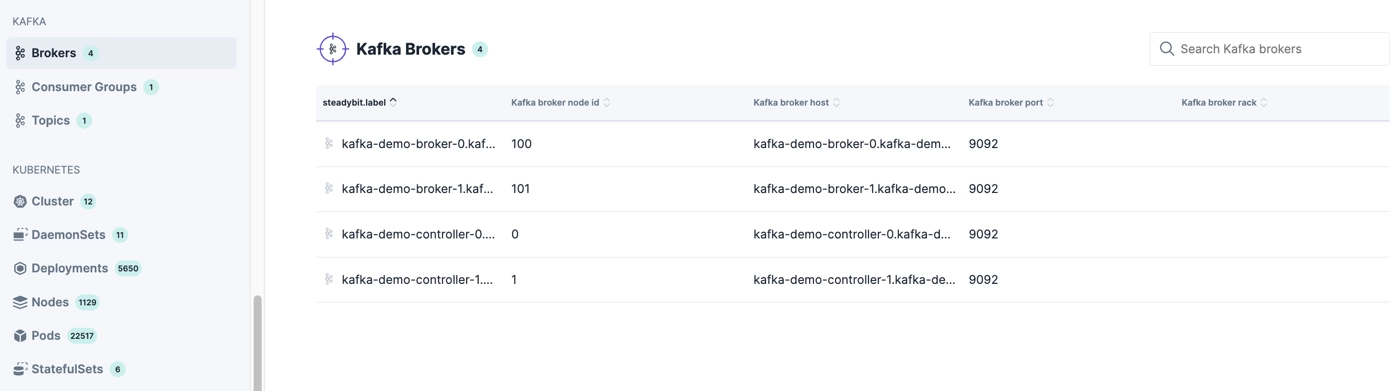
This extension automates the discovery of key Kafka components, including:
- Brokers
- Topics
- Consumer Groups
Each newly discovered target is enriched with attributes, making it easy to filter and select targets for your experiments.
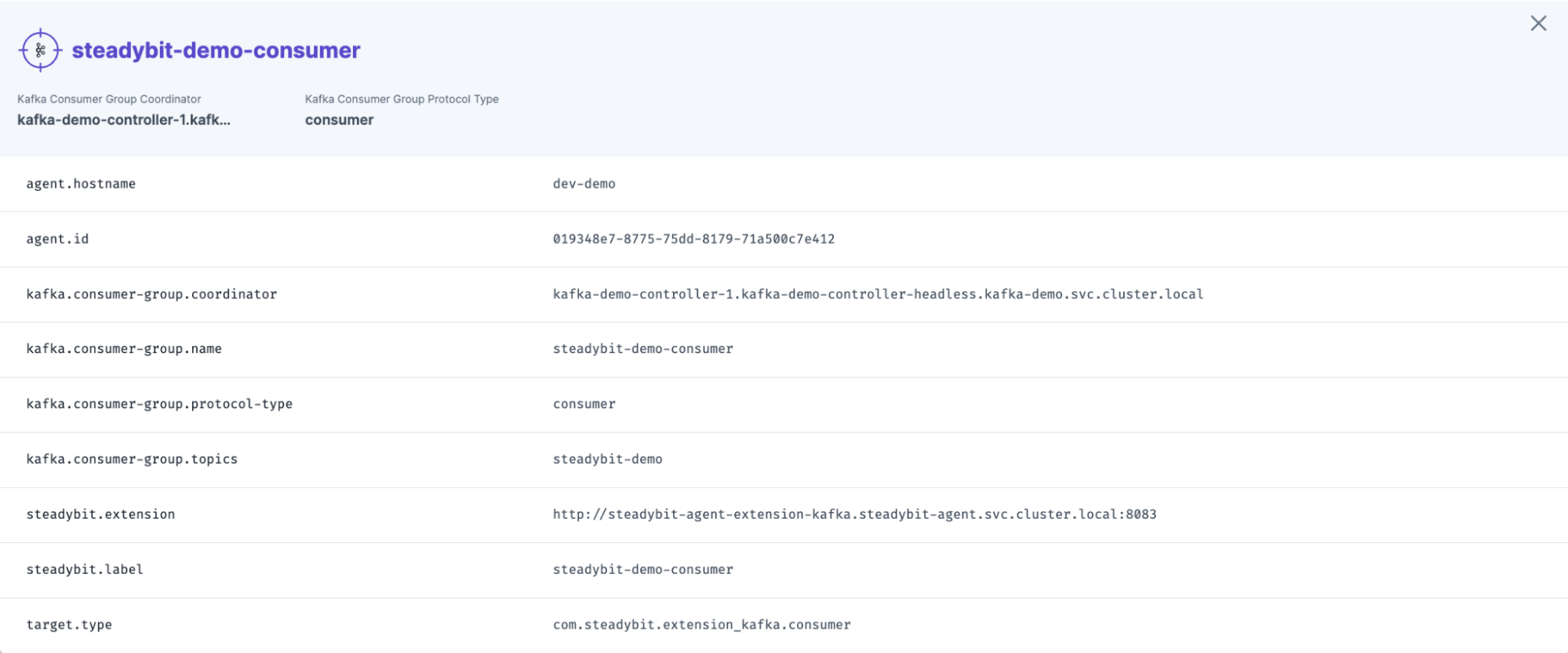
New Chaos Actions for Kafka
With the Kafka extension, you can simulate real-world scenarios using new, targeted actions such as:
Traffic Manipulation:
- Reduce the maximum batch size of messages.
- Limit IO/Network threads per broker.
- Restrict the rate of new connection creation.
Broker Management:
- Trigger leader elections for partitions.
Topic-Level Interventions:
- Produce records at a fixed rate or quantity.
- Deny consumer access to specific topics.
- Initiate delete record requests.
System State Validation:
- Check the current topic lag for consumer groups.
- Assess the state of a consumer group (e.g., rebalance or stable).
Example Experiment: Simulating a Kafka Traffic Jam
Imagine producing messages using the extension while simultaneously cutting network access for a targeted consumer group. This scenario creates significant lag, which can then be monitored using Steadybit’s checks to evaluate Kafka’s response to lost consumers. Key questions to explore:
- How fast can consumers recover from topic lag when brokers are back online?
- Does the consumer group state transition correctly (e.g., Empty → Prepare Rebalance → Stable)?
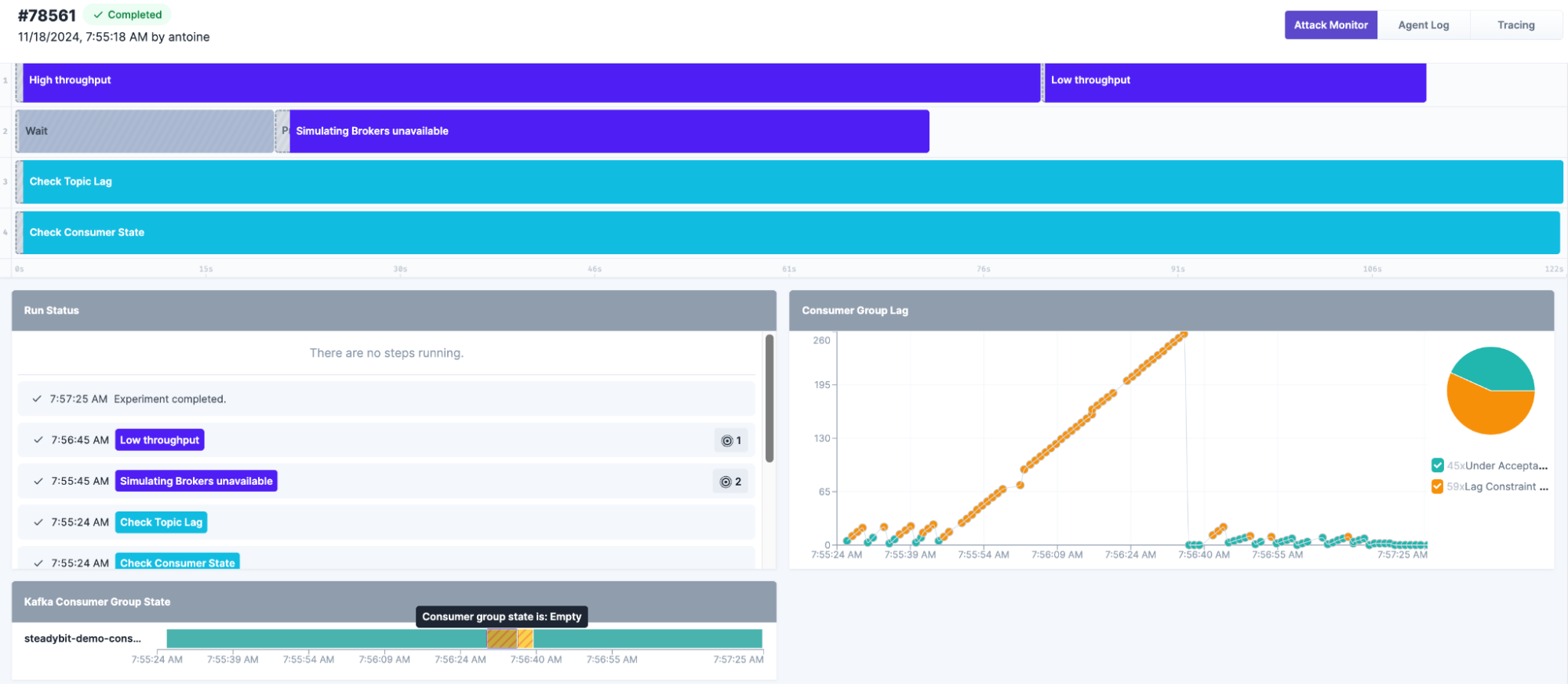
This controlled chaos experiment helps validate your consumers’ and brokers’ performance and resilience under real-world conditions.
Going Deeper: Exploring Broker Resiliency
How resilient is your Kafka setup when faced with broker failures? With Steadybit’s extension, you can simulate and analyze such scenarios in a controlled manner. Here’s how:
- Take down a broker to verify if the replication factor is sufficient to maintain availability.
- Test whether producers correctly wait for acknowledgments from multiple brokers before confirming a message as successfully produced.
A key aspect of broker resiliency lies in Kafka’s ability to rapidly elect new leaders among partition replicas during a failure. The speed and efficiency of this process are critical to avoiding disruptions. Let’s explore this through a focused experiment.
We simulate an artificial network outage for the broker currently leading a partition. Once the broker is restored, we force a new leader election to assess how the system handles the transition. During these events, Steadybit provides detailed insights into partition state changes, offering a clear view of Kafka’s adaptability under stress.
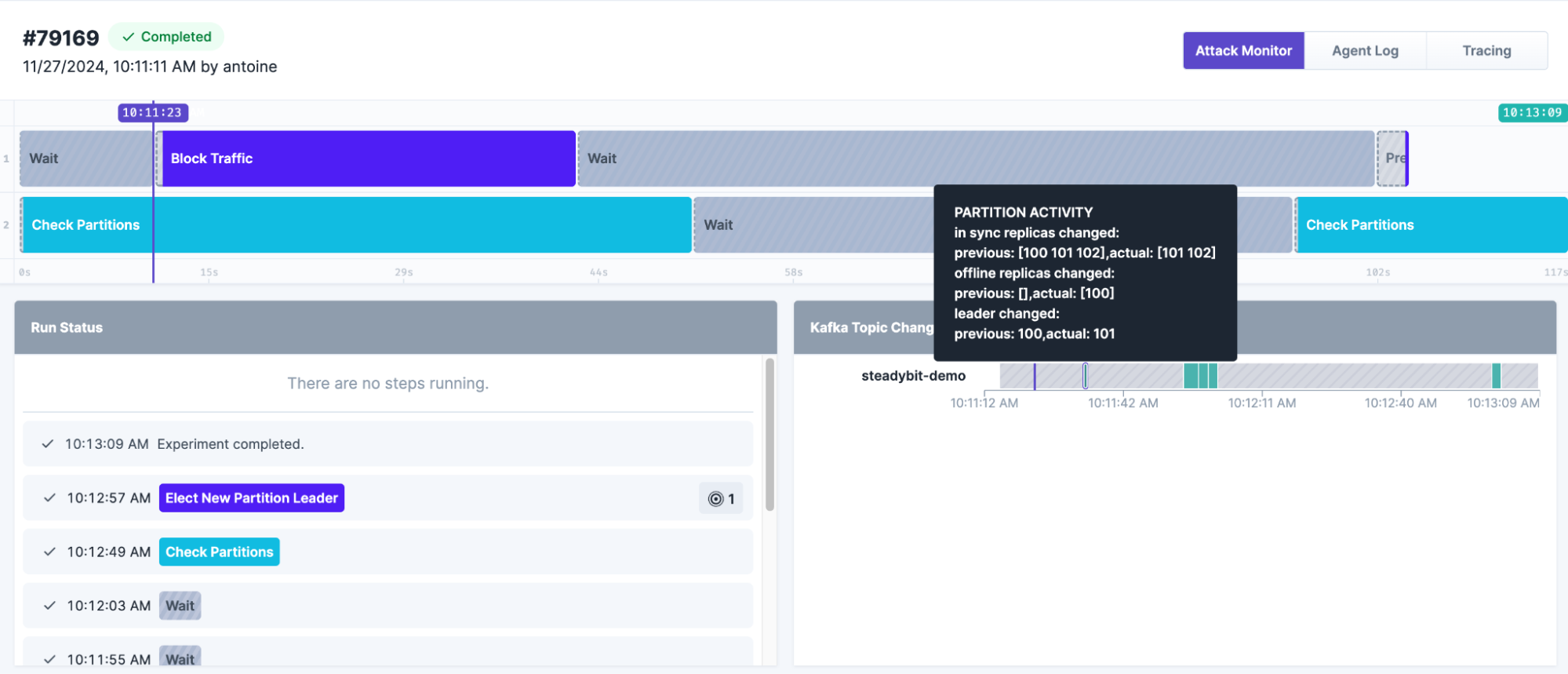
When the broker experiences downtime, Kafka promptly detects the issue, removing the broker from the list of synchronized replicas and marking it as an offline replica for the affected partition. Since this broker was the partition leader, Kafka also elects a new leader (in this case, broker 101). Impressively, Kafka completed this entire process in just 10 seconds, maintaining system stability and safety.
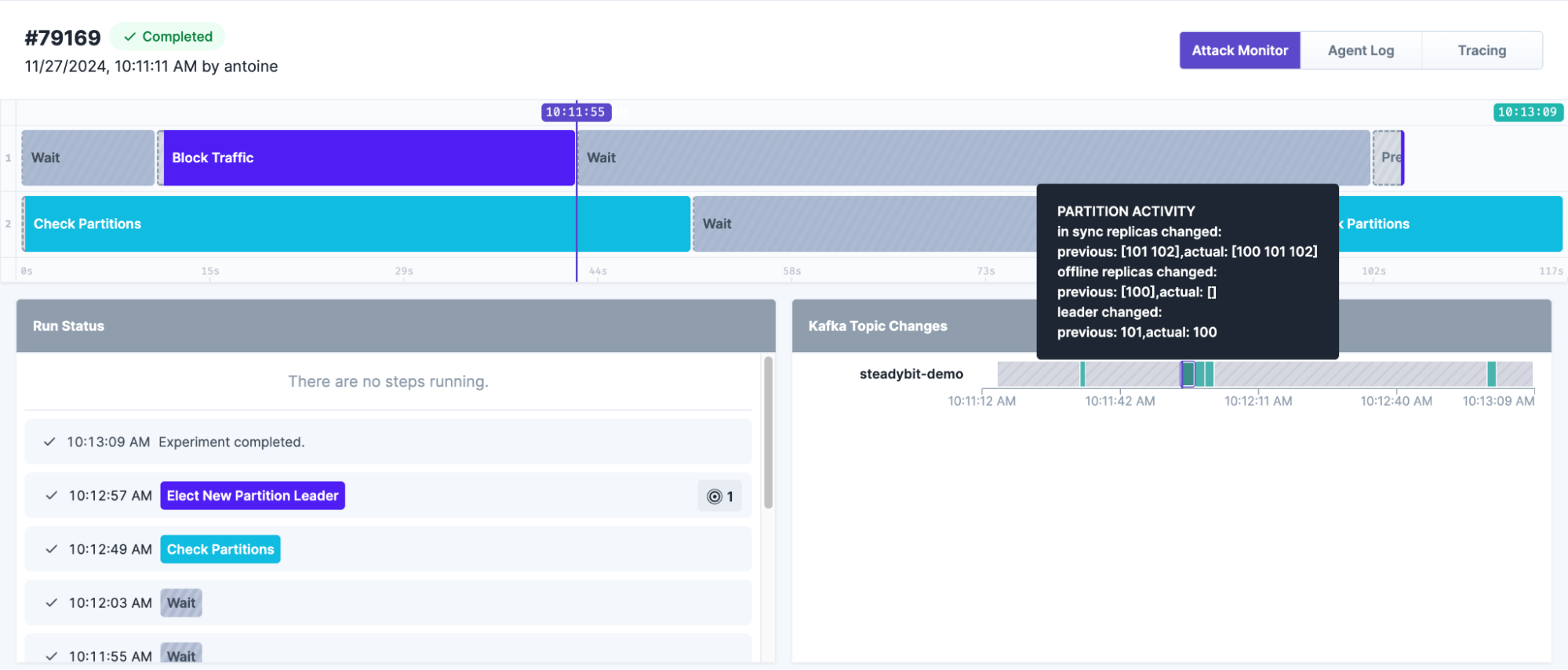
Later, when the broker’s traffic was restored, Kafka reintegrated it into the replica set almost instantaneously. To further test the system, we manually triggered another leader election—this time under normal operating conditions, without any outages. Remarkably, the election process was completed in just 2 seconds, demonstrating Kafka’s efficiency and readiness to handle leadership transitions seamlessly.
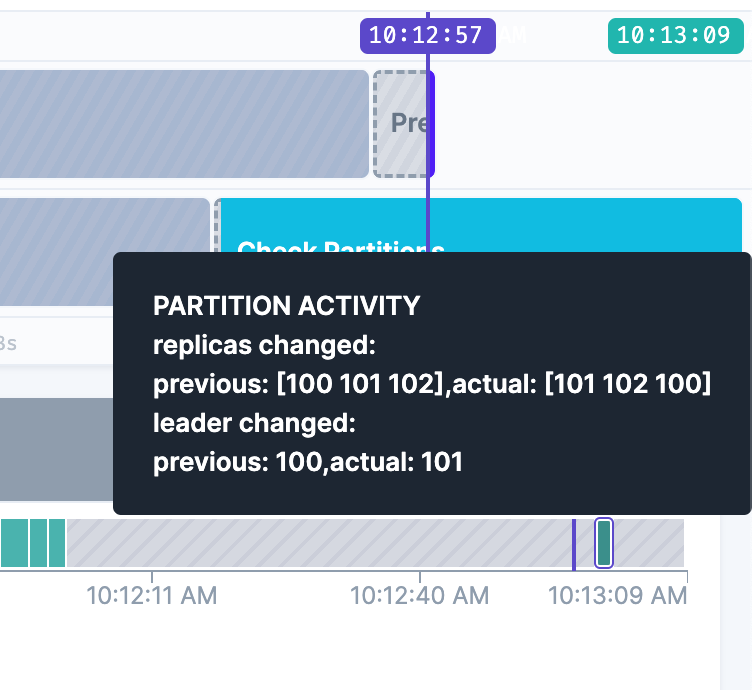
This experiment highlights how quickly and effectively Kafka can recover, ensuring continuous operations even in challenging conditions. By identifying potential weaknesses, you can bolster the resilience of your Kafka infrastructure.
Advanced Experimentation: Access Control and Missing Records
Beyond high-level disruptions, you can delve into finer-grained experiments:
- Use Kafka’s ACL mechanism to block a consumer from accessing a specific topic.
- Produce messages before, during, and after the access block.
- Delete records immediately after the access block and observe consumer behavior.
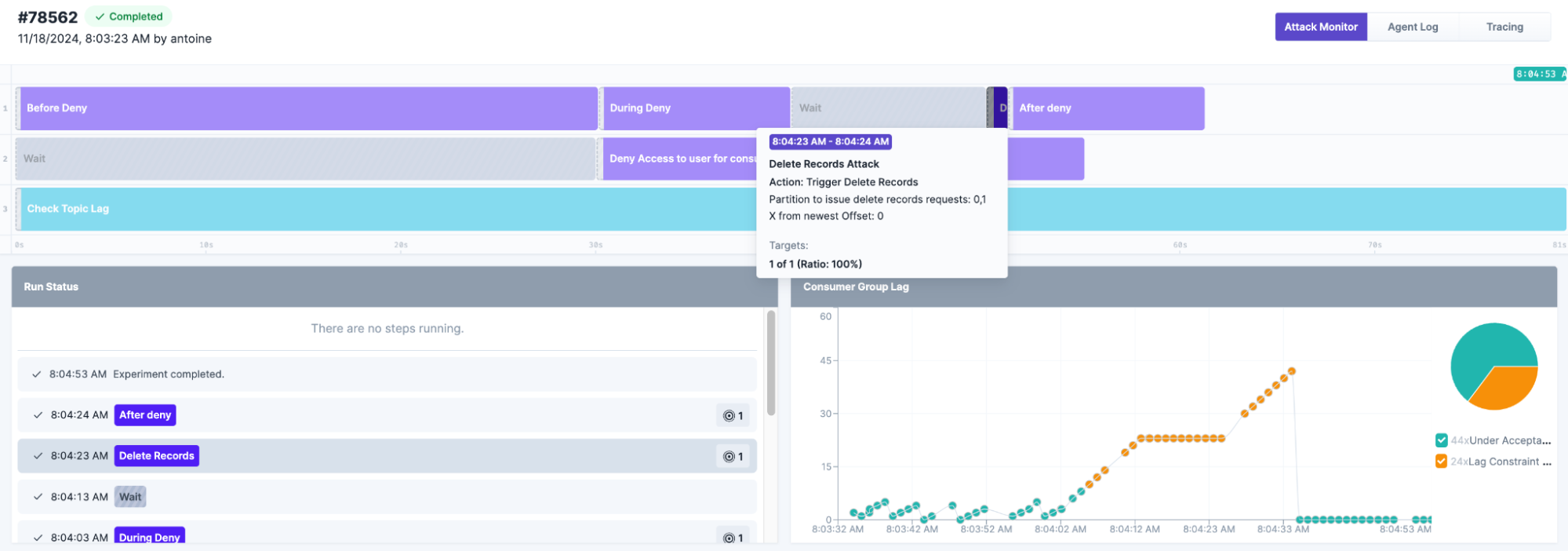
This setup allows you to answer critical questions:
- How does your consumer handle missing records?
- Does your observability system effectively detect and report these anomalies?
Learn More About Kafka Reliability
For more insights into Kafka reliability, we highly recommend watching the video How To Fail At Kafka by Peter Godfrey. It explores additional scenarios and questions worth considering in your chaos engineering endeavors.
With Steadybit’s Kafka extension, you can uncover vulnerabilities, validate recovery mechanisms, and ensure your Kafka clusters are robust enough to handle real-world disruptions.

Get started today
Full access to the Steadybit Chaos Engineering platform.
Available as SaaS and On-Premises!
or sign up with

Book a Demo
Let us guide you through a personalized demo to kick-start your Chaos Engineering efforts and build more reliable systems for your business!